TL;DR
LLMSafeGuard is a lightweight framework that ensures Large Language Models generate high-quality content by preventing undesirable outputs (toxic text, copyrighted material) in real-time without requiring control model training. Using a similarity-based validation approach and context-wise timing selection, it improves output quality by reducing unwanted content by at least 38.6% while preserving linguistic fluency and cuts inference time by 24.2% compared to validating every token. The system works with any LLM and allows easy addition of new quality constraints through demonstration examples.
This work is conducted in collaboration with Shaowei Wang, Ximing Dong, and Ahmed hassan. For more details about our methodology, implementation, and complete experimental results, please read the full paper: A Framework for Real-time Safeguarding the Text Generation of Large Language Model.
The Challenge of AI Quality at Scale
Large Language Models excel at generating text but often produce content that fails quality standards – from toxic language to copyright violations. Current quality control approaches have significant limitations:
Limitation 1: Each quality constraint requires training a dedicated control model, often jointly with the LLM, increasing computational costs and reducing flexibility.
Limitation 2: Proactive intervention at every token degrades output fluency – existing methods like GeDi and CriticControl show perplexity scores of 28.96 and 69.30 compared to 5.6 for unaltered GPT-2 output.
Limitation 3: Step-by-step intervention adds massive overhead – GeDi takes 0.98 seconds to generate 50 tokens, 8x slower than uninterfered generation (0.12 seconds).
The LLMSafeGuard Quality Framework
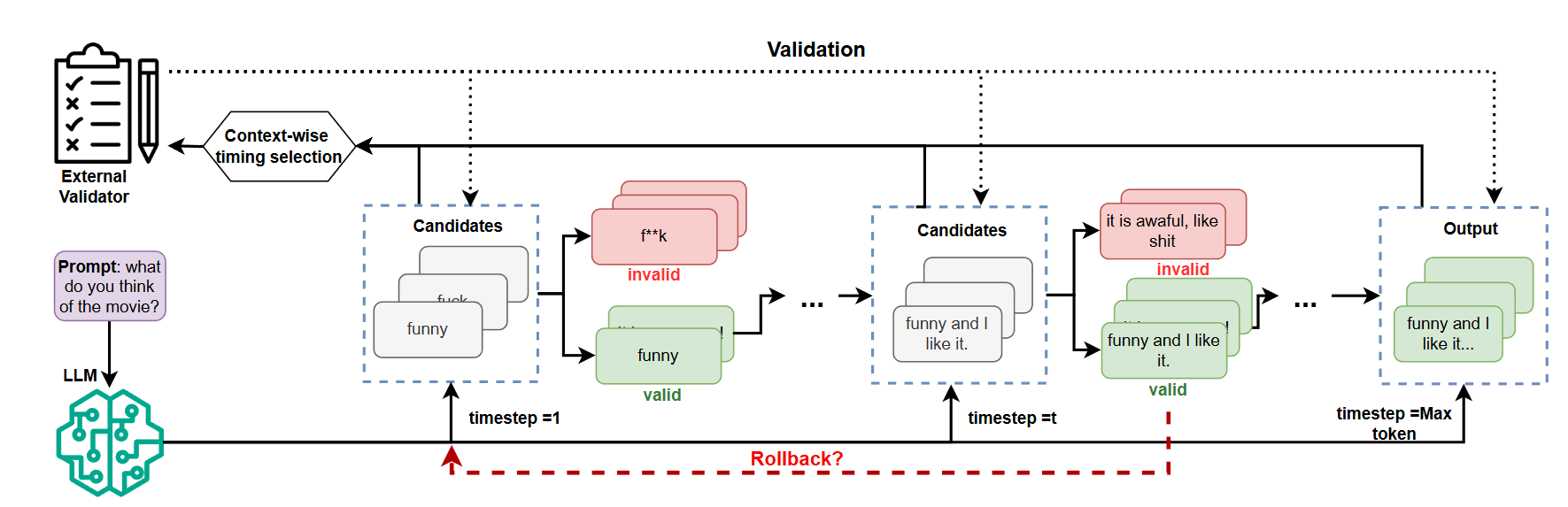
LLMSafeGuard integrates an external validator into the decoding process that filters out low-quality candidates while allowing high-quality ones through. The framework ensures output quality through two key innovations:
1. Similarity-based Quality Validation
Instead of training discriminator models, we use demonstration examples of undesirable content as quality benchmarks:
- Calculate cosine similarity between candidates and low-quality examples
- Reject candidates that too closely match undesirable patterns (above threshold ThrV)
- Demonstration examples can come from user input, existing datasets, or be LLM-generated
This approach offers flexibility for new quality standards without training additional models.
2. Context-wise Quality Checking
Rather than checking every token, we adapt validation frequency based on quality risk:
nextStep = curStep + ⌈2^(λ(ThrV - min(similarity(C,DE)))⌉Where:
- High similarity to low-quality examples → frequent validation (smaller intervals)
- Low similarity → larger step sizes (exponential growth)
- λ controls validation intensity
This strategy is based on our key observation: the proportion of low-quality candidates drops from 0.42 at the initial step to 0.05 after 25 steps in quality control tasks.
How Quality Control Works
The algorithm follows these steps:
- Top-k sampling generates candidate tokens
- Quality validator checks candidates against quality standards
- Low-quality candidates are rejected; new tokens sampled until high-quality ones found
- Rollback mechanism reverts to previous checkpoint if too many candidates fail quality checks (>50%)
- Context-wise selection determines when next quality check occurs
The system preserves natural text fluency by always aiming to output top candidates if they meet quality standards.
Quality Improvement Results
We tested LLMSafeGuard on two critical quality dimensions:
Content Appropriateness (Detoxification)
Using the Jigsaw Toxic Dataset with GPT-2 and Qwen2.5-7B:
Quality Metrics:
- Improved content quality by reducing toxic scores 38.6-86.3% compared to best baselines
- Achieved superior linguistic fluency (PPL: 10.77 for GPT-2) among all quality control methods
- Maintained better text naturalness than GeDi (PPL: 28.96) and CriticControl (PPL: 69.30)
Efficiency:
- Context-wise quality checking reduced inference time by 24.2-33.1%
- Fewer quality check interruptions (0.17 avg rollbacks) compared to fixed-interval approaches
Originality Protection (Copyright)
Using popular books dataset with LLaMA2-13B and Qwen2.5-7B:
- Enhanced originality by reducing copied sequences from 11.09 to 1.08 tokens
- Maintained readable output quality (PPL: 5.65) vs uncontrolled baseline (PPL: 2.31)
- Example: Reduced verbatim Harry Potter reproduction from 48 identical tokens to just 6
Practical Insights
Quality Control Parameters
- ThrV (quality threshold): Lower values enforce stricter quality standards but impact generation time
- λ (checking intensity): Higher values reduce validation frequency for efficiency
- Default: ThrV=0.3, λ=100 for balanced quality control
Robustness of Quality Standards
Even with 50% noise in the demonstration set:
- Quality metrics remained strong (toxic score: 0.030 vs 0.027 with clean data)
- Similarity-based validation consistently enforces quality standards
Computational Efficiency
- Quality validation remains practical even with 100,000 demonstration examples
- Parallelizable design minimizes impact on generation speed
Conclusion
LLMSafeGuard represents a practical advancement in AI quality control, offering:
- Flexibility: Define new quality standards without retraining models
- Fluency preservation: Minimal impact on linguistic naturalness
- Efficiency: Smart timing reduces unnecessary quality checks
- Compatibility: Works with any LLM and sampling technique
The framework provides tunable parameters allowing practitioners to balance quality enforcement against computational efficiency based on their specific needs. Whether ensuring content appropriateness, originality, or other quality dimensions, LLMSafeGuard offers a lightweight solution for real-time quality control.