TL;DR
IPOMP (Iterative evaluation data selection for effective Prompt Optimization using real-time Model Performance) is a two-stage approach that selects better evaluation data for optimizing LLM prompts. By combining semantic clustering with real-time performance feedback, IPOMP improves prompt optimization effectiveness by 1.6-3.1% and stability by 50-55.5% compared to existing methods, while adding less than 1% computational overhead. The real-time refinement approach can also enhance other data selection methods universally.
This work is conducted in collaboration with Shaowei Wang, Ximing Dong and Ahmed Hassan. For more details about our methodology, experimental setup, and complete results, please read the full paper: Model Performance-Guided Evaluation Data Selection for Effective Prompt Optimization.
The Hidden Cost of Random Evaluation Data
When optimizing prompts for Large Language Models, most approaches randomly select a small subset of training data to evaluate new prompts. This practice, while common, leads to:
- Unreliable evaluation results
- Suboptimal prompts
- Inconsistent performance
Existing coreset selection methods designed for ML benchmarking don’t work well for prompt optimization because:
- Semantic clustering fails when samples are naturally similar (e.g., navigation tasks)
- Performance-based methods require expensive pre-collection of model data
- Historical performance poorly predicts current LLM behavior
The IPOMP Solution: Two-Stage Intelligent Selection
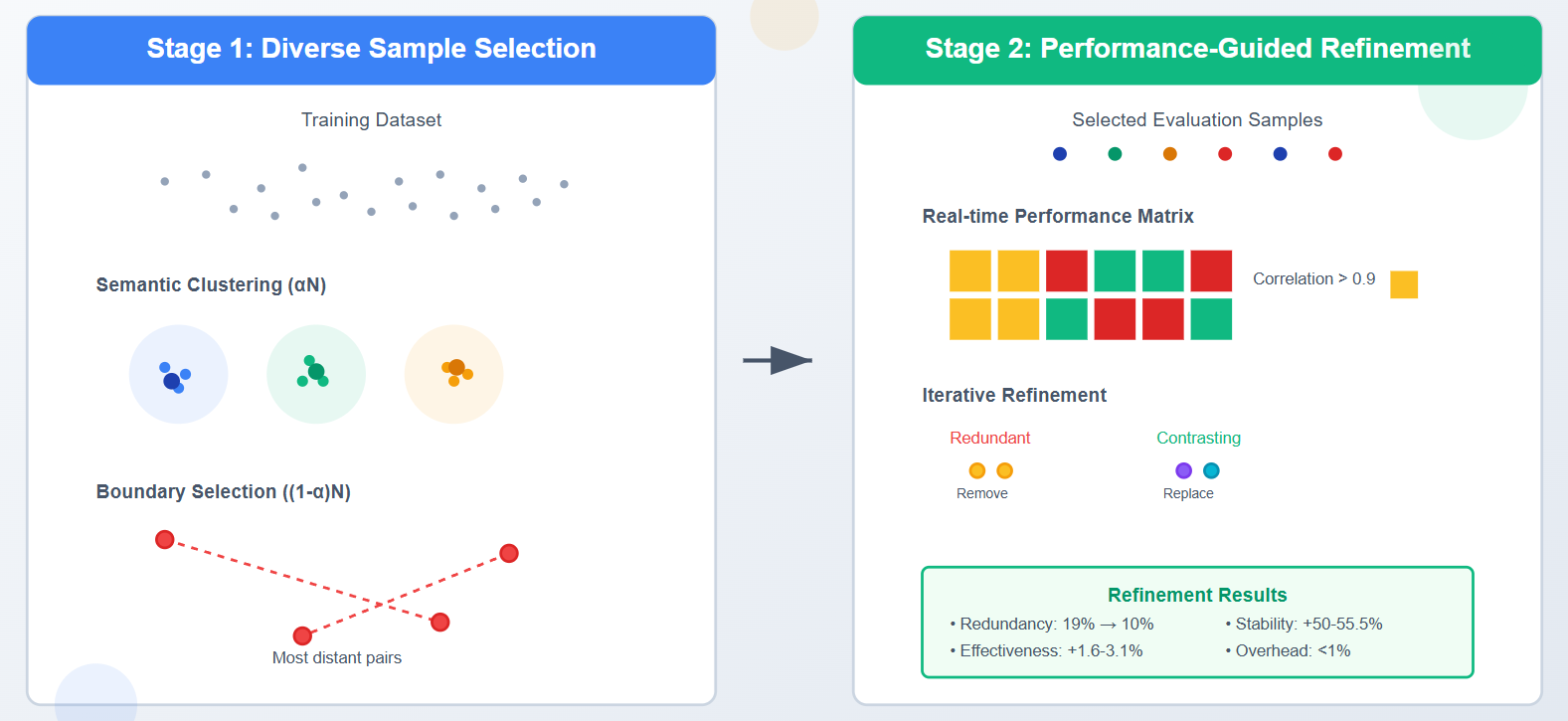
Stage 1: Diverse Sample Selection
IPOMP first builds a representative foundation by:
Semantic Clustering (αN samples):
- Embeds training samples using Sentence-BERT
- Clusters with K-means into k groups
- Selects proportionally from each cluster
Boundary Case Selection ((1-α)N samples):
- Identifies most distant sample pairs in semantic space
- Ensures edge cases are represented
- Prevents overlap with clustered samples
Stage 2: Real-time Performance-Guided Refinement
The key innovation: IPOMP dynamically improves selection during optimization by:
- Recording performance across candidate prompts (using logits)
- Identifying redundancy through correlation analysis (threshold: 0.9)
- Replacing redundant samples with contrasting ones from training set
Our key observation: 20% of samples show >0.9 correlation in model performance, indicating significant redundancy that can be optimized away.
Proven Results Across Multiple Dimensions
Effectiveness Improvements
Testing on BIG-bench and LIAR datasets with GPT-3.5 and GPT-4o-mini:
- IPOMP vs Best Baseline: 1.6-3.1% accuracy improvement
- IPOMP vs Random: Up to 10% improvement
- Consistent superiority across all prompt optimization techniques (APE, APO, EVOPROMPT)
Stability Gains
- 50-55.5% reduction in standard deviation compared to best baselines
- Stage 2 refinement reduces redundancy from 19% to 10% after first iteration
Minimal Overhead
- <1% computational overhead (average 2.83 seconds for Stage 2)
- No additional LLM inference costs (uses existing optimization data)
- Compared to Anchor-Point: 51% less overhead, no preliminary stage needed
Universal Enhancement Capability
IPOMP’s Stage 2 can enhance any existing data selection method:
- Random: +2.3% effectiveness, -18.8% standard deviation
- Boundary: +1.1% effectiveness, -60.0% standard deviation
- Clustering: +1.5% effectiveness, -6.9% standard deviation
- Anchor-Point: +0.3% effectiveness, -10.8% standard deviation
Case Study: Implicatures Task
Starting with 20 semantically diverse examples, IPOMP’s first refinement:
- Identified 7 highly correlated samples
- Replaced with contrasting examples (e.g., metaphorical vs literal responses)
- Reduced overall redundancy by 47%
Conclusion
IPOMP demonstrates that intelligent data selection significantly improves prompt optimization outcomes. By combining upfront semantic diversity with real-time performance feedback, it achieves better results with less computational cost than existing methods.
The framework’s modular design allows the performance-guided refinement to enhance any data selection approach, making it a practical upgrade for existing prompt optimization pipelines. As LLMs become more integral to software systems, efficient prompt optimization through better evaluation data selection becomes increasingly critical.