TL;DR
Real-time Adaptive Routing (RAR) is a method that dynamically routes requests between stronger (expensive) and weaker (cheaper) Foundation Models while continuously improving the weaker model’s capabilities through guided in-context learning. On MMLU benchmark subsets, RAR reduced expensive model usage by 50.2% while maintaining 90.5% of response quality compared to an ideal static router. The system learns from stronger models’ reasoning to help weaker models handle increasingly complex tasks over time.
This work is done in collaboration with Kirill Vasilevski and Ahmed Hassan. For more details about our methodology, implementation, and future directions, please read the full paper: Real-time Adapting Routing (RAR): Improving Efficiency Through Continuous Learning in Software Powered by Layered Foundation Models.
The Cost-Quality Dilemma in Foundation Model Deployment
Foundation Models (FMs) like large language models have become integral to modern software applications, from chatbots to code generation tools. However, developers face a fundamental trade-off: larger models with hundreds of billions of parameters deliver superior capabilities but require magnitudes more expensive computing resources compared to smaller models with only a few billion parameters.
This has led to the emergence of layered architectures where:
- Simple requests go to small, cost-efficient models
- Complex requests fall back to large, expensive models
- The routing decision determines overall system efficiency
The challenge? Existing routing solutions have significant limitations:
- They rely on static training data that may not generalize well
- Updating routing decisions requires expensive retraining
- They miss opportunities for weaker models to improve over time
Introducing Real-time Adaptive Routing (RAR)
RAR addresses these limitations through a dynamic approach that combines intelligent routing with continuous learning. The system has two main objectives:
- Maintain capability levels as close as possible to the stronger FM
- Maximize usage of the weaker FM to reduce computational costs
How RAR Works
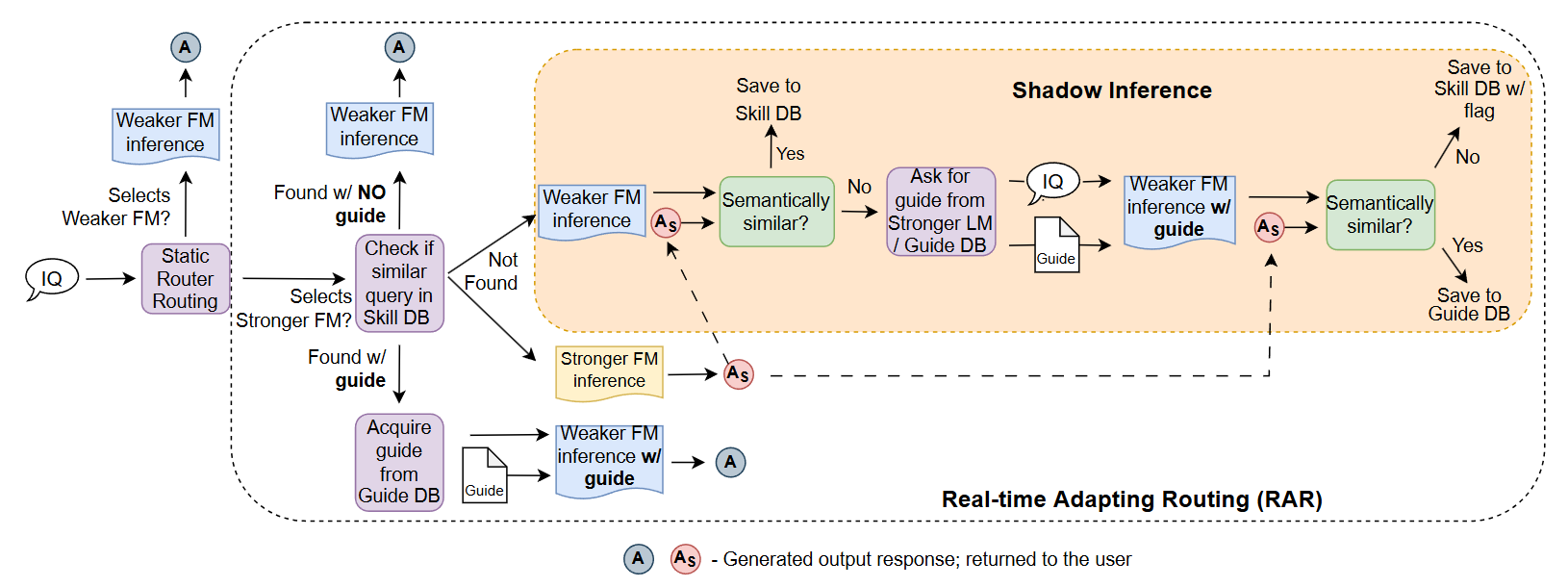
When a request arrives, RAR follows this process:
Initial Routing: A pre-trained static router (like those in RouteLLM) makes an initial routing decision based on request characteristics.
Shadow Inference: When the static router selects the stronger model, RAR performs “shadow inference” in the background:
- The request goes to the stronger FM and returns to the user immediately
- Simultaneously, the weaker FM attempts the same request
- The system compares both responses to identify improvement opportunities
Three Possible Outcomes:
- Case 1 – Standalone Success: If the weaker FM generates a similar response without help, future similar requests go directly to the weaker model
- Case 2 – Success with Guide: If the weaker FM fails alone but succeeds with a guide (reasoning hints from the stronger model), the system saves this guide for future use
- Case 3 – Failure: If the weaker FM fails even with guidance, the request is flagged for stronger model routing
The Power of Guides
Guides are instructions or hints generated by stronger models that help weaker models reason through problems without containing the actual answer. For example, a guide might suggest “Consider the constitutional principles involved” rather than providing the specific legal answer.
These guides are stored in a vector database (skill and guide memory) and can be reused for similar future requests, enabling knowledge transfer across different queries.
Evaluation Results
We evaluated RAR on subsets of the MMLU (Massive Multitask Language Understanding) benchmark, focusing on questions that Mistral-7B (weaker model) initially failed to answer correctly. We used GPT-4o and Llama-3-70B as stronger models.
Key Findings
Cost Reduction: RAR achieved a 50.2% reduction in stronger FM usage compared to an ideal oracle static router (p < 0.001).
Quality Maintenance: Despite dramatic cost reduction, overall response quality remained at 90.5% of the oracle router baseline.
Performance Improvements: RAR showed:
- 349% improvement over standalone weaker FM
- 135% improvement over weaker FM with Chain-of-Thought prompting
- Maintained 89.5% performance compared to standalone stronger FM
Generalization Capabilities
The guides demonstrated two types of generalization:
Intra-domain: Within the same subject area (e.g., professional law), guide reuse increased by 44.4% over 4 stages, showing that guides generated for one question could help with related questions.
Inter-domain: Surprisingly, guides from one domain (professional law) improved performance in other domains by 6-7% for high-school psychology and moral scenarios, suggesting some transferable reasoning patterns.
Real-World Applications
RAR is particularly valuable for:
Cloud-based Services: Services like ChatGPT could route simple queries to cheaper models while reserving expensive models for complex tasks.
Edge Computing: Smartphones could use on-device models for most tasks, only calling cloud models when necessary, improving:
- Privacy (data stays on device)
- Latency (no network round-trip)
- Cost (reduced cloud compute)
- Personalization (guides cached locally)
Conclusion
RAR represents a practical advancement in making AI systems more cost-effective without sacrificing quality. By combining adaptive routing with continuous learning from stronger models, it creates a system that becomes more efficient over time—exactly what’s needed as AI becomes ubiquitous in software applications.
The 50% reduction in expensive model usage while maintaining 90% quality demonstrates significant optimization potential in current AI deployments. As foundation models continue growing in size and cost, approaches like RAR will become essential for sustainable AI system design.