Dayi Lin, Ph.D.
Tag:
动态规划
August 19, 2013
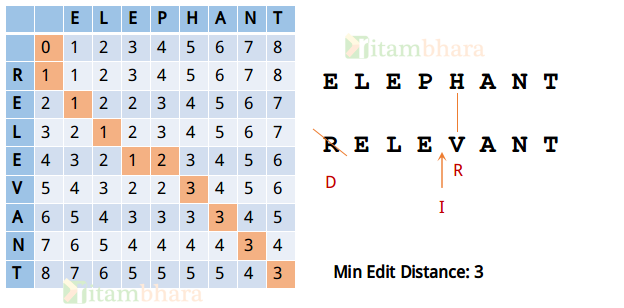
最小编辑距离 算法原理
August 11, 2013
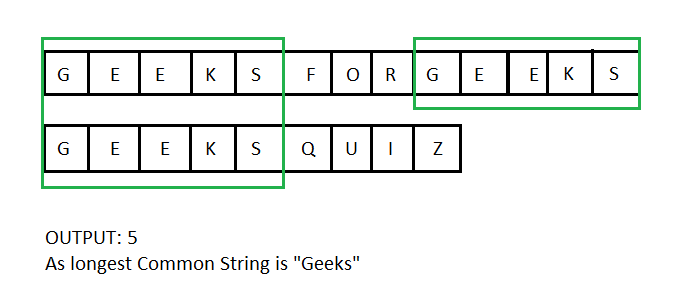
LCS(最长公共子序列)