Dayi Lin, Ph.D.
Search
About
Publications
Services
Projects
Contact
Author:
Dayi Lin
May 8, 2018
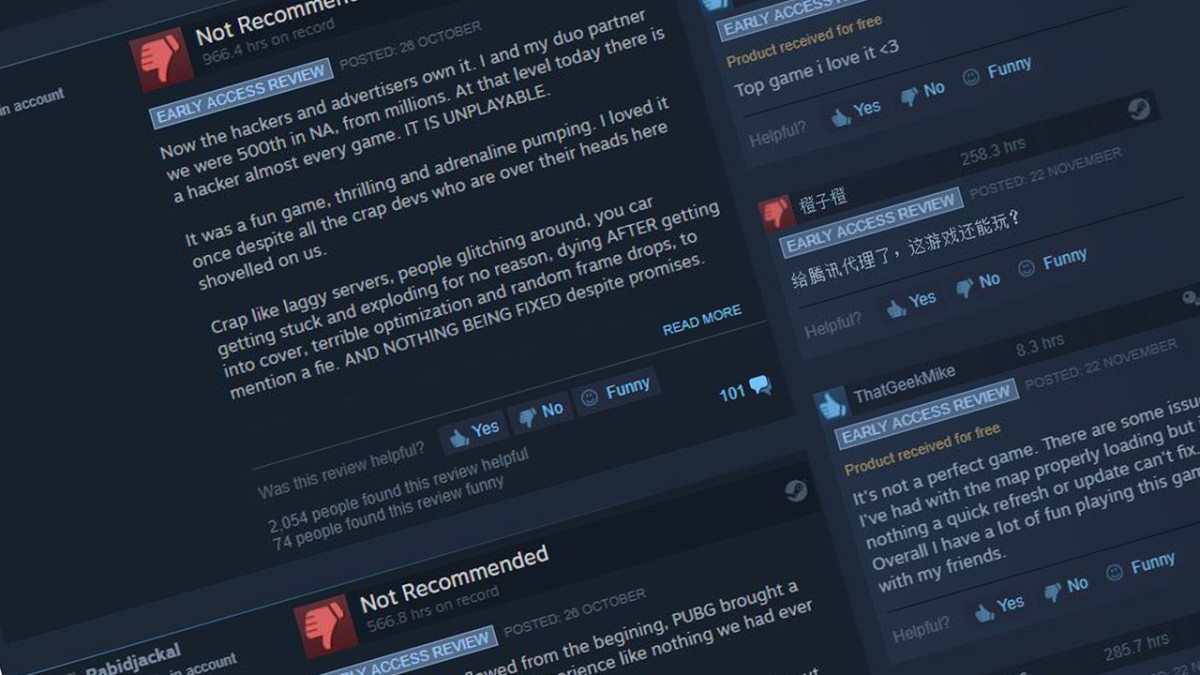
Our recent research about game reviews is covered in medias including Kotaku, PC Gamers, Rock Paper Shotgun, and Gamasutra!
June 22, 2017
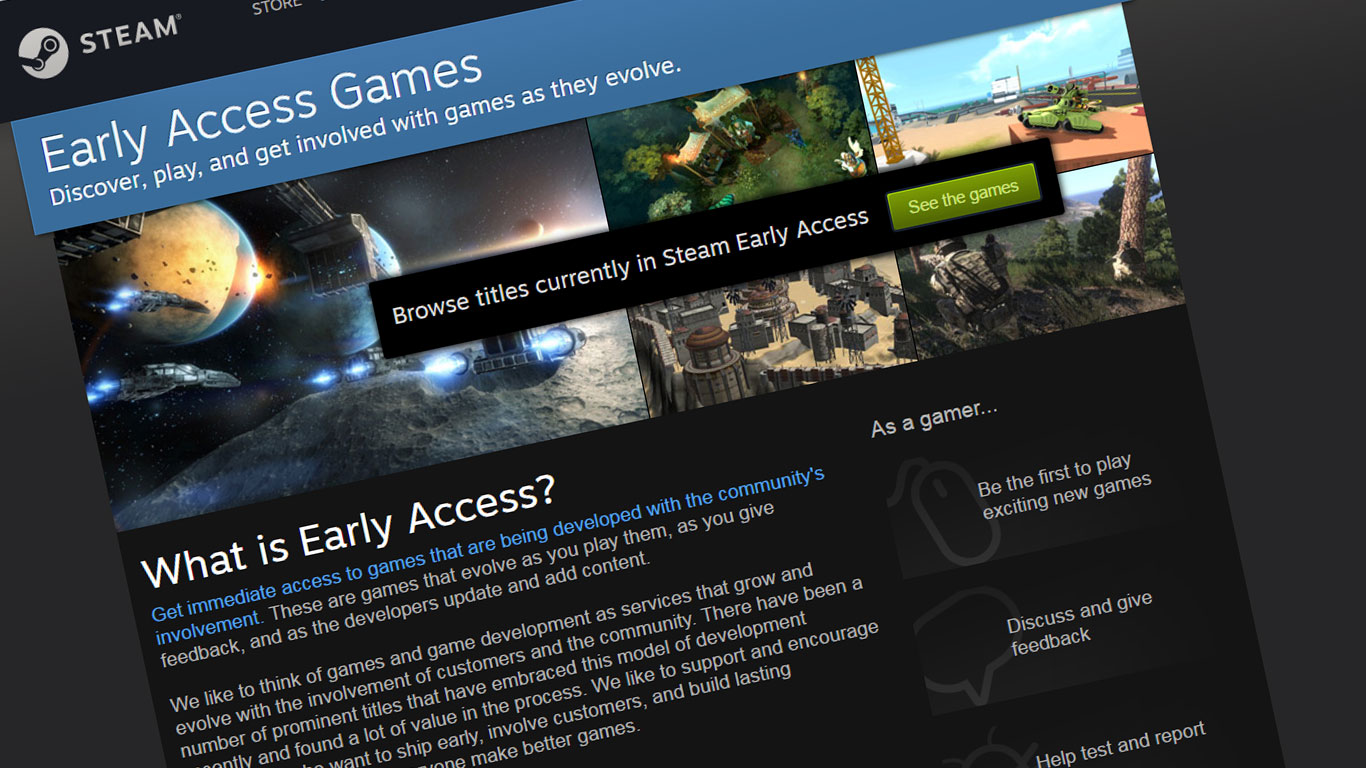
Our Latest Research about Early Access Games was Covered by Kotaku!
May 8, 2015
[Behind CS] CS平台设计随笔 – 综述
July 26, 2014
托福心得
July 22, 2014
[7.22实习笔记] 校招实习生百阿百技培训笔记
August 19, 2013
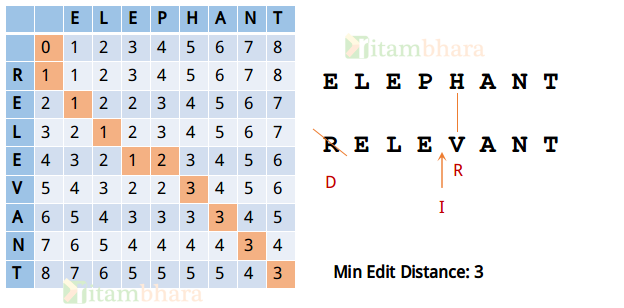
最小编辑距离 算法原理
August 11, 2013
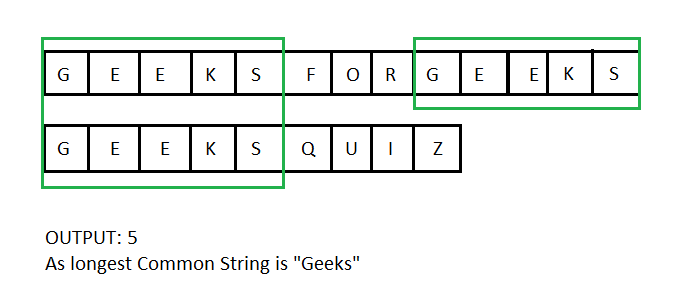
LCS(最长公共子序列)
July 28, 2013
打造群博2:借助WP-o-Matic实现RSS自动抓取
July 28, 2013
打造群博1:将WP模板首页显示全文改为显示摘要
October 12, 2012
POJ-1258 解题报告
1
2
3
Next
→
![[Behind CS] CS平台设计随笔 – 综述](https://lindayi.me/wp-content/uploads/2015/05/CS技术架构.png)

![[7.22实习笔记] 校招实习生百阿百技培训笔记](https://lindayi.me/wp-content/uploads/2014/07/buying-from-alibaba.jpg)