Dayi Lin, Ph.D.
Search
About
Publications
Services
Projects
Contact
Author:
Dayi Lin
October 11, 2012
POJ-2240 解题报告
October 9, 2012
POJ-1125 解题报告
October 6, 2012
POJ-1062 解题报告
October 5, 2012
POJ-2253 解题报告
July 23, 2012
POJ-1860 解题报告
July 21, 2012
POJ-3259 解题报告
July 21, 2012
POJ-3295 解题报告
July 20, 2012
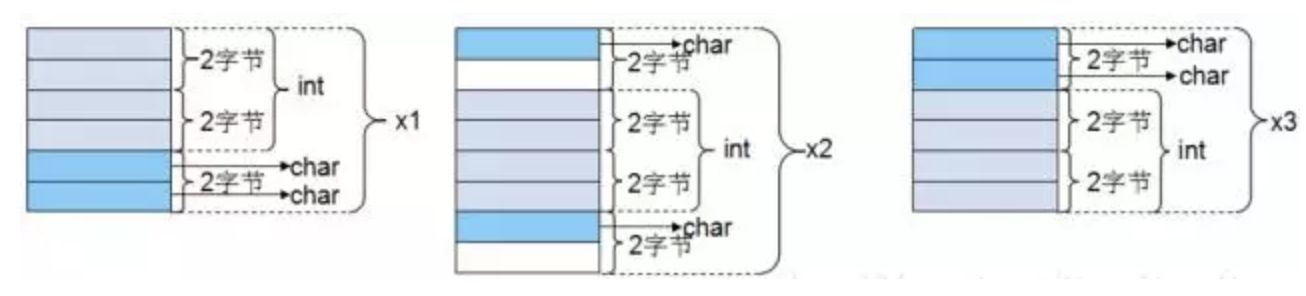
关于对齐规则
July 15, 2012
POJ-2993 解题报告
July 14, 2012
POJ-2996 解题报告
←
Previous
1
2
3
Next
→